GEMV with Checkerboard Pattern
Contents
GEMV with Checkerboard Pattern¶
This example shows a CSL program that performs generalized matrix-vector (GEMV) multiplication operation of the form:
y = Ax + b
where:
Ais a tensor of shape [M, N] (stored distributed on PE memory).xis a tensor input of shape [N, 1] (streamed in).bis a tensor input of shape [M, 1] (streamed in).yis the tensor output of shape [M, 1] (streamed out).
For simplicity, we choose M as a multiple of the height of the kernel and N as a multiple of the width of the kernel. In this example, M = 32, N = 16 and we use a PE-rectangle (kernel) of size 4×4.
Below is a visualization of the kernel interface:
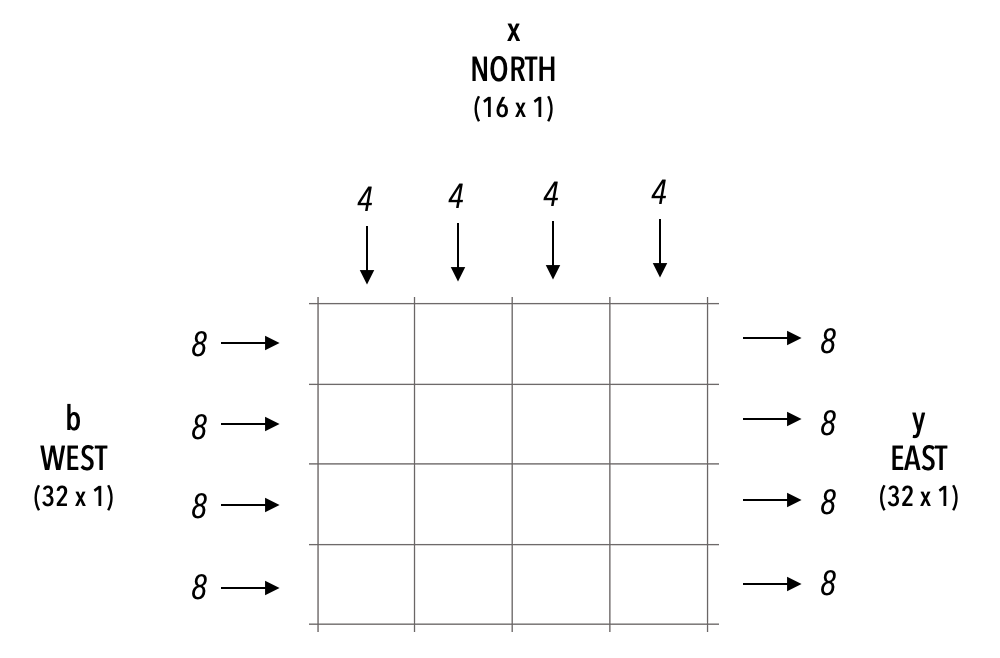
Note that this algorithm and the implementation are not optimized for performance. It is intended to serve as a non-trivial introductory example.
All computations are done in FP16 format.
The matrix A, of shape [M, N],
is distributed across the PE memories as follows:
The first dimension of
A, M rows, is distributed across the height of the kernel.The second dimension of
A, N columns, is distributed across the width of the kernel.
Since we know that M is 32 and the height of the kernel is 4, each PE will be
assigned 32÷4 = 8 rows of A.
Similarly, each PE will get 16÷4 = 4 columns of A. This means each PE is
assigned an 8×4 chunk of the original matrix A.
layout.csl¶
// The core kernel must start at P4.1 so the memcpy infrastructure has enough
// resources to route the data between the host and the device.
//
// color map of histogram-torus + memcpy:
//
// color var color var color var color var
// 0 9 LAUNCH 18 27 reserved (memcpy)
// 1 x_in 10 H2D_1 19 28 reserved (memcpy)
// 2 11 H2D_2 20 29 reserved
// 3 ax_out 12 D2H 21 reserved (memcpy) 30 reserved (memcpy)
// 4 b_in 13 22 reserved (memcpy) 31 reserved
// 5 14 23 reserved (memcpy) 32
// 6 15 24 C_REDUCE 33
// 7 16 25 34
// 8 17 26 35
//
// This does y = Ax + b where
// the matrix A is matrix_rows-by-matrix_cols,
// the vector x is matrix_cols-by-1,
// the vector b/y is matrix_rows-by-1.
//
// The core rectangle is w-by-h where
// w = kernel_cols and h = kernel_rows.
param MEMCPYH2D_DATA_1_ID: i16;
param MEMCPYH2D_DATA_2_ID: i16;
param MEMCPYD2H_DATA_1_ID: i16;
param LAUNCH_ID: i16;
param x_in : color; // color for input X from NORTH to kernel
// These colors are involved in the checkerboard pattern
param b_in : color; // color for input B from WEST to kernel
param ax_out : color; // alternate color for passing result towards EAST
// Program uses 4x4 rectangle of PEs
param kernel_rows : i16; // Height of kernel
param kernel_cols : i16; // Width of kernel
// Global A, B, X dims
param matrix_rows : i16; // Height of matrix
param matrix_cols : i16; // Width of matrix
const MEMCPYH2D_DATA_1: color = @get_color(MEMCPYH2D_DATA_1_ID);
const MEMCPYH2D_DATA_2: color = @get_color(MEMCPYH2D_DATA_2_ID);
const MEMCPYD2H_DATA_1: color = @get_color(MEMCPYD2H_DATA_1_ID);
const LAUNCH: color = @get_color(LAUNCH_ID);
const C_REDUCE: color = @get_color(24);
const A_rows : i16 = matrix_rows;
const A_cols : i16 = matrix_cols;
const X_rows : i16 = matrix_cols;
const X_cols : i16 = 1;
const B_rows : i16 = matrix_rows;
const B_cols : i16 = 1;
// A, B, X dims per PE
const A_local_dim_x : i16 = A_rows / kernel_rows;
const A_local_dim_y : i16 = A_cols / kernel_cols;
const X_local_dim_x : i16 = X_rows / kernel_rows;
const X_local_dim_y : i16 = X_cols;
const B_local_dim_x : i16 = B_rows / kernel_rows;
const B_local_dim_y : i16 = B_cols;
const memcpy = @import_module( "<memcpy_multi/get_params>", .{
.width = kernel_cols,
.height = kernel_rows
});
layout {
// @set_rectangle takes width and height arguments in order.
@set_rectangle(kernel_cols, kernel_rows);
const same_colors = .{.x_in=x_in, .recv = b_in, .send = ax_out };
const swapped_colors = .{.x_in=x_in, .recv = ax_out, .send = b_in };
const dimensions = .{ .A_local_dim_x = A_local_dim_x,
.A_local_dim_y = A_local_dim_y,
.X_local_dim_x = X_local_dim_x,
.X_local_dim_y = X_local_dim_y,
.B_local_dim_x = B_local_dim_x,
.B_local_dim_y = B_local_dim_y };
for (@range(i16, kernel_cols)) |i| {
for (@range(i16, kernel_rows)) |j| {
const memcpy_params = memcpy.get_params(i);
const last_column: bool = (i == kernel_cols - 1);
const dim_memcpy = @concat_structs( .{
.memcpy_params = memcpy_params,
.LAUNCH = LAUNCH,
.MEMCPYH2D_DATA_1 = MEMCPYH2D_DATA_1,
.MEMCPYH2D_DATA_2 = MEMCPYH2D_DATA_2,
.MEMCPYD2H_DATA_1 = MEMCPYD2H_DATA_1,
.C_REDUCE = C_REDUCE,
.last_column = last_column
}, dimensions);
if (i % 2 == 1) {
@set_tile_code(i, j, "pe.csl", @concat_structs(dim_memcpy, swapped_colors));
} else {
@set_tile_code(i, j, "pe.csl", @concat_structs(dim_memcpy, same_colors));
}
}
}
// Create route values
const RX_R_TX_RS = .{.rx=.{RAMP}, .tx=.{RAMP, SOUTH}};
const RX_N_TX_RS = .{.rx=.{NORTH}, .tx=.{RAMP, SOUTH}};
const RX_N_TX_R = .{.rx=.{NORTH}, .tx=.{RAMP}};
const RX_W_TX_R = .{.rx=.{WEST}, .tx=.{RAMP}};
const RX_R_TX_E = .{.rx=.{RAMP}, .tx=.{EAST}};
const RX_R_TX_R = .{.rx=.{RAMP}, .tx=.{RAMP}};
for (@range(i16, kernel_cols)) |i| {
for (@range(i16, kernel_rows)) |j| {
// TODO: first column receives data from streaming H2D
// On even columns, b_in is "recv" color, receiving values
// from west and transmitted down ramp for computation.
// On odd columns, b_in is "send" color, receiving values
// up ramp and sending to east.
// On last column, however, b_in is not used.
// On leftmost (0th) column, b_in receives B from the host.
if (i == 0){
@set_color_config(i, j, b_in, .{.routes = RX_R_TX_R });
}else{
if (i % 2 == 0) {
@set_color_config(i, j, b_in, .{.routes = RX_W_TX_R });
} else {
@set_color_config(i, j, b_in, .{.routes = RX_R_TX_E });
}
}
// On even columns, ax_out is "send" color, receiving values
// up ramp and sending to east.
// On odd columns, ax_out is "recv" color, receiving values
// from west and transmitting down ramp for computation.
if (i % 2 == 0) {
@set_color_config(i, j, ax_out, .{.routes = RX_R_TX_E });
} else {
@set_color_config(i, j, ax_out, .{.routes = RX_W_TX_R });
}
// first row receives data from streaming H2D
// All rows transmit X values down ramp for computation.
// All rows except last row must also propagate X values south.
// The last row will not propagate X values.
if (j == kernel_rows - 1) {
@set_color_config(i, j, x_in, .{.routes = RX_N_TX_R});
} else if (j == 0 ){
@set_color_config(i, j, x_in, .{.routes = RX_R_TX_RS});
} else {
@set_color_config(i, j, x_in, .{.routes = RX_N_TX_RS});
}
}
}
// export symbol name
@export_name("A", [*]f16, true);
}
pe.csl¶
// This does y = Ax + b
param memcpy_params: comptime_struct;
param LAUNCH: color;
param MEMCPYH2D_DATA_1: color; // 1st row receives x
param MEMCPYH2D_DATA_2: color; // 1st column receives b
param MEMCPYD2H_DATA_1: color; // last column sends out y
param x_in: color; // receive x from north except 1st row
// the data is broadcasted by 1st row
// checkerboard color for sending result to EAST
param send: color;
// checkerboard color for receiving result from WEST except 1st column
param recv: color;
// entrypoint to perform chain reduction when y = A*x is done
param C_REDUCE: color;
// dims of A, X, B chunks on PE
param A_local_dim_x : i16;
param A_local_dim_y : i16;
param X_local_dim_x : i16;
param X_local_dim_y : i16;
param B_local_dim_x : i16;
param B_local_dim_y : i16;
param last_column: bool;
// memcpy reserves input queue 0 and output queue 0
const sys_mod = @import_module( "<memcpy_multi/memcpy>", @concat_structs(memcpy_params, .{
.MEMCPYH2D_1 = MEMCPYH2D_DATA_1,
.MEMCPYH2D_2 = MEMCPYH2D_DATA_2,
.MEMCPYD2H_1 = MEMCPYD2H_DATA_1,
.LAUNCH = LAUNCH
}));
// A is A_local_dim_x-by-A_local_dim_y in row-major
var A = @zeros([A_local_dim_x, A_local_dim_y]f16);
// mul_temp holds A*x
export var mul_temp = @zeros([A_local_dim_x]f16);
var ptr_A: [*]f16 = &A;
const dsd_A = @get_dsd(mem1d_dsd, .{ .tensor_access = |i|{A_local_dim_x} -> A[i, 0], .wavelet_index_offset=true});
const dsd_mul_temp = @get_dsd(mem1d_dsd, .{ .tensor_access = |i|{A_local_dim_x} -> mul_temp[i]});
const dsd_in = @get_dsd(fabin_dsd, .{
.fabric_color = recv,
.extent = B_local_dim_x,
.input_queue = @get_input_queue(1)
});
export var num_recv_x: i16 = 0;
// receive xj = x[j]
// compute y(:) += A(:,j)*xj
// When WTT finishes, y = A*x, compute y = A*x + y_west
task fmac_task(wlet_data : f16, idx : u16) void {
@fmach(dsd_mul_temp, dsd_mul_temp, dsd_A, wlet_data, .{.index = idx});
num_recv_x += 1;
// trigger chain reduction when last xj is received and y = A*x is done
if (num_recv_x >= X_local_dim_x){
@activate(C_REDUCE);
}
}
// "reduce_task" is called by all PEs after y = A*x is done
// 1st column receives b from MEMCPYH2D_DATA_2 and forwards it to color "recv"
// other columns receive partial result from the west
//
// All PEs perform y = A*x + y_west
//
// last column sends final result y via streaming D2H (MEMCPYD2H_DATA_1)
// other columns send the partial result to the EAST
//
// The host waits until D2H receives y --> y = A*x is done
task reduce_task() void {
const dsd_out = @get_dsd(fabout_dsd, .{
.fabric_color = if (last_column) MEMCPYD2H_DATA_1 else send,
.extent = B_local_dim_x,
.output_queue = @get_output_queue(2)
});
@faddh(dsd_out, dsd_in, dsd_mul_temp, .{ .async = true });
}
comptime {
@bind_task(fmac_task, x_in);
// recv is blocked because microthread is used
@block(recv);
}
var buf = @zeros([1]u32);
const mem_buf_dsd = @get_dsd(mem1d_dsd, .{ .tensor_access = |i|{1} -> buf[i] });
const fab_trans_x_wdsd = @get_dsd(fabout_dsd, .{
.extent = 1,
.fabric_color = x_in,
.output_queue = @get_output_queue(5)
});
// 1st row receives x from MEMCPYH2D_DATA_1, then
// forwards data to the whole column, including itself, via color "x_in"
task wtt_memcpyh2d_x( data : u32 ) void {
@block(MEMCPYH2D_DATA_1);
buf[0] = data;
@mov32(fab_trans_x_wdsd, mem_buf_dsd, .{.async=true, .unblock=MEMCPYH2D_DATA_1} );
}
const fab_trans_b_wdsd = @get_dsd(fabout_dsd, .{
.extent = 1,
.fabric_color = recv,
.output_queue = @get_output_queue(5)
});
// 1st column receives b from MEMCPYH2D_DATA_2, then
// forwards data to itself via color "recv"
task wtt_memcpyh2d_b( data : u32 ) void {
@block(MEMCPYH2D_DATA_2);
buf[0] = data;
@mov32(fab_trans_b_wdsd, mem_buf_dsd, .{.async=true, .unblock=MEMCPYH2D_DATA_2} );
}
comptime{
@comptime_assert(X_local_dim_y == 1);
@comptime_assert(B_local_dim_y == 1);
@bind_task(wtt_memcpyh2d_x, MEMCPYH2D_DATA_1);
@bind_task(wtt_memcpyh2d_b, MEMCPYH2D_DATA_2);
@bind_task(reduce_task, C_REDUCE);
}
comptime{
@export_symbol(ptr_A, "A");
@rpc(LAUNCH);
}
run.py¶
#!/usr/bin/env cs_python
import argparse
import json
import numpy as np
from cerebras.sdk.sdk_utils import memcpy_view
from cerebras.sdk.debug.debug_util import debug_util
from cerebras.sdk.runtime import runtime_utils # pylint: disable=no-name-in-module
from cerebras.sdk.runtime.sdkruntimepybind import SdkRuntime, MemcpyDataType # pylint: disable=no-name-in-module
from cerebras.sdk.runtime.sdkruntimepybind import MemcpyOrder # pylint: disable=no-name-in-module
parser = argparse.ArgumentParser()
parser.add_argument("--name", help="the test name")
parser.add_argument("--cmaddr", help="IP:port for CS system")
parser.add_argument("--debug", help="debug", action="store_true")
args = parser.parse_args()
dirname = args.name
# Parse the compile metadata
with open(f"{dirname}/out.json", encoding="utf-8") as json_file:
compile_data = json.load(json_file)
compile_params = compile_data["params"]
kernel_rows = int(compile_params["kernel_rows"]) # Height of kernel
kernel_cols = int(compile_params["kernel_cols"]) # Width of kernel
A_rows = int(compile_params["matrix_rows"]) # number of rows of A
A_cols = int(compile_params["matrix_cols"]) # number of columns of A
MEMCPYH2D_DATA_1 = int(compile_params["MEMCPYH2D_DATA_1_ID"])
MEMCPYH2D_DATA_2 = int(compile_params["MEMCPYH2D_DATA_2_ID"])
MEMCPYD2H_DATA_1 = int(compile_params["MEMCPYD2H_DATA_1_ID"])
print(f"MEMCPYH2D_DATA_1 = {MEMCPYH2D_DATA_1}")
print(f"MEMCPYH2D_DATA_2 = {MEMCPYH2D_DATA_2}")
print(f"MEMCPYD2H_DATA_1 = {MEMCPYD2H_DATA_1}")
print(f"Program runs on a {kernel_cols}x{kernel_rows} rectangle of PEs")
# Create tensors for A, X, B.
print(f"the matrix A is A_rows-by-A_cols, A_cols = {A_cols}, A_rows = {A_rows}")
X_rows = A_cols
X_cols = 1
B_rows = A_rows
B_cols = 1
# Use a deterministic seed so that CI results are predictable
np.random.seed(seed=7)
if args.debug:
A = np.arange(A_rows*A_cols).reshape(A_rows, A_cols).astype(np.float16)
X = np.arange(X_rows*X_cols).reshape(X_rows, X_cols).astype(np.float16)
B = np.zeros((B_rows, B_cols), np.float16)
else:
A = np.random.rand(A_rows, A_cols).astype(np.float16)
X = np.random.rand(X_rows, X_cols).astype(np.float16)
B = np.random.rand(B_rows, B_cols).astype(np.float16)
if args.debug:
print(f"A = {A}")
print(f"X = {X}")
print(f"B = {B}")
# Compute expected result
expected = (A @ X) + B
memcpy_dtype = MemcpyDataType.MEMCPY_16BIT
runner = SdkRuntime(dirname, cmaddr=args.cmaddr)
sym_A = runner.get_id("A")
runner.load()
runner.run()
# Split A tensor across PEs
# A[M, N] -> kernel_cols * kernel_rows * A[M // kernel_cols, N // kernel_rows]
per_pe_rows = A_rows // kernel_rows
per_pe_cols = A_cols // kernel_cols
print(f"the local size of y: per_pe_rows = {per_pe_rows}")
print(f"the local size of x: per_pe_cols = {per_pe_cols}")
# Example: w=2, h=2, A is 4-by-4
# A = | 0 1 2 3 |
# | 4 5 6 7 |
# | 8 9 10 11 |
# | 12 13 14 15 |
# A1 = A.reshape(2,2,2,2)
# A1 = | | 0 1| | 4 5| |
# | | 2 3|, | 6 7| |
# | |
# | | 8 9| |12 13| |
# | |10 11|, |14 15| |
# A2 = A1.transpose(0, 2, 1, 3)
# A2 = | | 0 1| | 2 3| |
# | | 4 5|, | 6 7| |
# | |
# | | 8 9| |10 11| |
# | |12 13|, |14 15| |
# A3 = A2.reshape(2,2,4)
# A3 = | 0 1 4 5 |
# | 2 3 6 7 |
# | 8 9 12 13 |
# | 10 11 14 15 |
# A3 is h-w-l
A1 = A.reshape(kernel_rows, per_pe_rows,
kernel_cols, per_pe_cols)
A2 = A1.transpose(0, 2, 1, 3)
A3 = A2.reshape(kernel_rows, kernel_cols, per_pe_rows*per_pe_cols)
print("step 1: copy mode H2D A")
A_1d_u32 = runtime_utils.input_array_to_u32(np_arr=A3.ravel(), sentinel=0, \
fast_dim_sz=per_pe_rows*per_pe_cols)
runner.memcpy_h2d(sym_A, A_1d_u32, 0, 0, kernel_cols, kernel_rows, per_pe_rows*per_pe_cols, \
streaming=False, data_type=memcpy_dtype, order=MemcpyOrder.ROW_MAJOR, nonblock=True)
print("step 2: streaming mode H2D X at 1st row via color MEMCPYH2D_DATA_1")
print(" each PE receives x, performs local A*x and triggers chain reduction")
# extend x with index in the upper 16-bit
x_1d_u32 = runtime_utils.input_array_to_u32(np_arr=X.ravel(), sentinel=1, fast_dim_sz=per_pe_cols)
runner.memcpy_h2d(MEMCPYH2D_DATA_1, x_1d_u32, 0, 0, kernel_cols, 1, per_pe_cols,\
streaming=True, data_type=memcpy_dtype, order=MemcpyOrder.ROW_MAJOR, nonblock=True)
print("step 3: streaming mode H2D B at 1st column via color MEMCPYH2D_DATA_2")
print(" 1st column receives B to start the chain reduction, others wait for data from the west")
# extend x with zero in the upper 16-bit
b_1d_u32 = runtime_utils.input_array_to_u32(np_arr=B.ravel(), sentinel=0, fast_dim_sz=per_pe_rows)
runner.memcpy_h2d(MEMCPYH2D_DATA_2, b_1d_u32, 0, 0, 1, kernel_rows, per_pe_rows,\
streaming=True, data_type=memcpy_dtype, order=MemcpyOrder.ROW_MAJOR, nonblock=True)
print("step 4: streaming mode D2H y at last column via color MEMCPYD2H_DATA_1")
print(" this D2H indidates the y = A*x is done")
y_1d_u32 = np.zeros(B_rows, np.uint32)
runner.memcpy_d2h(y_1d_u32, MEMCPYD2H_DATA_1, kernel_cols-1, 0, 1, kernel_rows, per_pe_rows, \
streaming=True, data_type=memcpy_dtype, order=MemcpyOrder.ROW_MAJOR, nonblock=False)
# remove upper 16-bit of each u32
result_tensor = memcpy_view(y_1d_u32, np.dtype(np.float16))
result_tensor = result_tensor.reshape(B_rows, B_cols)
runner.stop()
np.testing.assert_allclose(result_tensor, expected, atol=0.01, rtol=0)
print("SUCCESS!")
if args.debug:
debug_mod = debug_util(dirname, cmaddr=args.cmaddr)
core_fabric_offset_x = 4
core_fabric_offset_y = 1
print(f"=== dump core: core_fabric {core_fabric_offset_x}, {core_fabric_offset_y}")
# local A*x
Ax_hwl = np.zeros((kernel_rows, kernel_cols, per_pe_rows), np.float16)
for py in range(kernel_rows):
for px in range(kernel_cols):
t = debug_mod.get_symbol(core_fabric_offset_x+px, core_fabric_offset_y+py,\
'mul_temp', np.float16)
Ax_hwl[py, px, :] = t
print(f"Ax_hwl = \n{Ax_hwl}")
x_hwl = np.zeros((kernel_rows, kernel_cols, per_pe_cols), np.float16)
for py in range(kernel_rows):
for px in range(kernel_cols):
t = debug_mod.get_symbol(core_fabric_offset_x+px, core_fabric_offset_y+py,\
'x_temp', np.float16)
x_hwl[py, px, :] = t
print(f"x_hwl = \n{x_hwl}")
num_recv_x_hwl = np.zeros((kernel_rows, kernel_cols, 1), np.int16)
for py in range(kernel_rows):
for px in range(kernel_cols):
t = debug_mod.get_symbol(core_fabric_offset_x+px, core_fabric_offset_y+py,\
'num_recv_x', np.int16)
num_recv_x_hwl[py, px, :] = t
print(f"num_recv_x_hwl = \n{num_recv_x_hwl}")
commands.sh¶
#!/usr/bin/env bash
set -e
cslc ./layout.csl --fabric-dims=11,6 --fabric-offsets=4,1 \
--colors=x_in:1,ax_out:3,b_in:4 -o out \
--params=kernel_rows:4,kernel_cols:4,matrix_rows:32,matrix_cols:16 \
--params=MEMCPYH2D_DATA_1_ID:10 --params=MEMCPYH2D_DATA_2_ID:11 \
--params=MEMCPYD2H_DATA_1_ID:12 --params=LAUNCH_ID:9 \
--memcpy --channels=1 --width-west-buf=0 --width-east-buf=0
cs_python run.py --name out